
Usually, when Google scrapes a content website to provide its content to users in search results ahead of the actual search results, they’re looking for premium editorial content. Sometimes I also see Google scraping structured data, especially when it’s marked up carefully. But here’s something I don’t recall ever having seen:
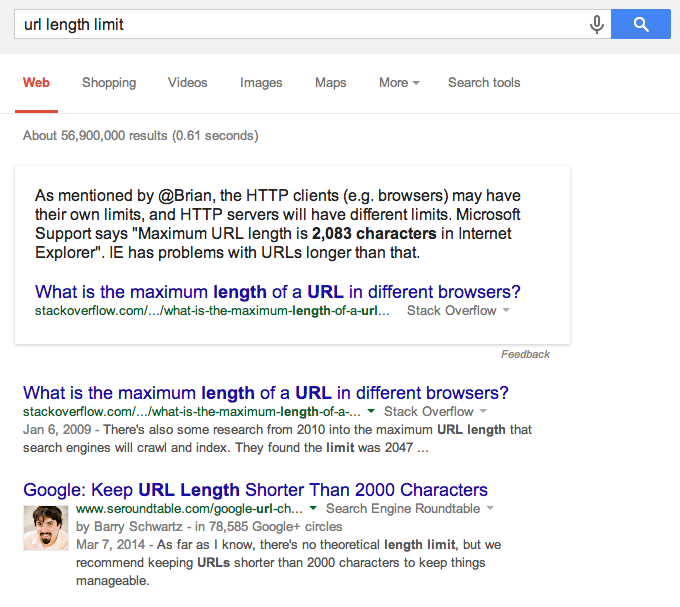
In this case, I searched for [url length limit] to get information on best practices, and Google scraped part of an answer to a question on Stack Overflow.
Here’s the question: What is the maximum length of a URL in different browsers?. The winning answer was ignored. The answer that Google scraped was the sixth most popular answer, out of 11, and directly referred to the second most popular answer.
This seems like a mistake to me. I’ve occasionally had terrible experiences with Stack Exchange in the past and, while I do consider that a great resource, would not consider any site in the network a good candidate for white-listed inclusion in an answer scraping program.